# Colab users, uncomment and run this
#!pip install -q icechunk virtualizarr xarray obspec_utils obstore hvplot s3fsVirtualiZarr → Icechunk in Cloud Storage → Append days
Author: Eli Holmes modification of Rich Signell’s notebook
Workflow
- Open a single nc file on S3 and create a virtual dataset
- Write virtual references to an Icechunk store in cloud storage
- Open the next nc file on S3 and create a virtual dataset
- Append to the Icechunk store
- Repeat
import warnings
import shutil
from pathlib import Path
import xarray as xr
import icechunk
from obstore.store import from_url
from virtualizarr import open_virtual_dataset, open_virtual_mfdataset
from virtualizarr.parsers import HDFParser
from obspec_utils.registry import ObjectStoreRegistry
warnings.filterwarnings(
"ignore",
message="Numcodecs codecs are not in the Zarr version 3 specification*",
category=UserWarning,
)Set up the urls to the REMOTE files in object storage
Start by looking at what is in the bucket and seeing how the data are organized.
import s3fs
bucket = "s3://noaa-cdr-ndvi-pds"
fs = s3fs.S3FileSystem(anon=True)
fs.ls(bucket)['noaa-cdr-ndvi-pds/data',
'noaa-cdr-ndvi-pds/documentation',
'noaa-cdr-ndvi-pds/index.html']# Let's look at what is in data
fs.ls(f"{bucket}/data")['noaa-cdr-ndvi-pds/data/1981',
'noaa-cdr-ndvi-pds/data/1982',
'noaa-cdr-ndvi-pds/data/1983',
'noaa-cdr-ndvi-pds/data/1984',
'noaa-cdr-ndvi-pds/data/1985',
'noaa-cdr-ndvi-pds/data/1986',
'noaa-cdr-ndvi-pds/data/1987',
'noaa-cdr-ndvi-pds/data/1988',
'noaa-cdr-ndvi-pds/data/1989',
'noaa-cdr-ndvi-pds/data/1990',
'noaa-cdr-ndvi-pds/data/1991',
'noaa-cdr-ndvi-pds/data/1992',
'noaa-cdr-ndvi-pds/data/1993',
'noaa-cdr-ndvi-pds/data/1994',
'noaa-cdr-ndvi-pds/data/1995',
'noaa-cdr-ndvi-pds/data/1996',
'noaa-cdr-ndvi-pds/data/1997',
'noaa-cdr-ndvi-pds/data/1998',
'noaa-cdr-ndvi-pds/data/1999',
'noaa-cdr-ndvi-pds/data/2000',
'noaa-cdr-ndvi-pds/data/2001',
'noaa-cdr-ndvi-pds/data/2002',
'noaa-cdr-ndvi-pds/data/2003',
'noaa-cdr-ndvi-pds/data/2004',
'noaa-cdr-ndvi-pds/data/2005',
'noaa-cdr-ndvi-pds/data/2006',
'noaa-cdr-ndvi-pds/data/2007',
'noaa-cdr-ndvi-pds/data/2008',
'noaa-cdr-ndvi-pds/data/2009',
'noaa-cdr-ndvi-pds/data/2010',
'noaa-cdr-ndvi-pds/data/2011',
'noaa-cdr-ndvi-pds/data/2012',
'noaa-cdr-ndvi-pds/data/2013',
'noaa-cdr-ndvi-pds/data/2014',
'noaa-cdr-ndvi-pds/data/2015',
'noaa-cdr-ndvi-pds/data/2016',
'noaa-cdr-ndvi-pds/data/2017',
'noaa-cdr-ndvi-pds/data/2018',
'noaa-cdr-ndvi-pds/data/2019',
'noaa-cdr-ndvi-pds/data/2020',
'noaa-cdr-ndvi-pds/data/2021',
'noaa-cdr-ndvi-pds/data/2022',
'noaa-cdr-ndvi-pds/data/2023',
'noaa-cdr-ndvi-pds/data/2024',
'noaa-cdr-ndvi-pds/data/2025',
'noaa-cdr-ndvi-pds/data/2026']# Let's look at what is in data; looks like daily based on file names
fs.ls(f"{bucket}/data/2000")[:5]['noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000101_c20170623095628.nc',
'noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000102_c20170623101557.nc',
'noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000103_c20170623103338.nc',
'noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000104_c20170623105028.nc',
'noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000105_c20170623110559.nc']# Create urls for first 5 days of 2000
prefix = "s3://"
filenames = fs.ls(f"{bucket}/data/2000")[:5]
urls = [f"{prefix}{f}" for f in filenames]
urls['s3://noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000101_c20170623095628.nc',
's3://noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000102_c20170623101557.nc',
's3://noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000103_c20170623103338.nc',
's3://noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000104_c20170623105028.nc',
's3://noaa-cdr-ndvi-pds/data/2000/AVHRR-Land_v005_AVH13C1_NOAA-14_20000105_c20170623110559.nc']Setup S3 store, registry and Icechunk config for REMOTE files
Point obstore at the public NDVI bucket and register it so VirtualiZarr can resolve chunk references.
# Create an object-store handle for the REMOTE files.
store = from_url(bucket, region="us-east-1", skip_signature=True)
registry = ObjectStoreRegistry({bucket: store})
parser = HDFParser()This will be passed to icechunk functions.
# Tell the store how to access the remote chunks
config = icechunk.RepositoryConfig.default()
config.set_virtual_chunk_container(
icechunk.VirtualChunkContainer(
url_prefix="s3://noaa-cdr-ndvi-pds/",
store=icechunk.s3_store(region="us-east-1", anonymous=True),
),
)Set up the Icechunk storage bucket
Source Coop makes it easy to get this info via a ‘View Credentials’ link. Since I am working in a Jupyter notebook, I will load the variables via a json file.
- Create a json file and add to
.gitignoreso you do not accidentally commit it to GitHub. Never hard-code tokens into notebooks. - Get the bucket info: provider (S3, GCP, etc), bucket, prefix and pass that to set up the storage object.
# Read in the json file
import json
from pathlib import Path
with open("source-creds.json") as f:
source_creds = json.load(f)# This info you get from your storage
source_bucket = "us-west-2.opendata.source.coop"
source_prefix = "eeholmes/chlaz/icechunk"
source_region = "us-west-2"
storage = icechunk.s3_storage(
bucket=source_bucket,
prefix=source_prefix,
region=source_creds["region_name"],
access_key_id=source_creds["aws_access_key_id"],
secret_access_key=source_creds["aws_secret_access_key"],
session_token=source_creds["aws_session_token"],
)# Create store if it is empty
try:
repo = icechunk.Repository.create(storage, config)
print("Created new Icechunk repo")
except Exception:
repo = icechunk.Repository.open(storage, config=config)
print("Opened existing Icechunk repo")
# Create a session
session = repo.writable_session(branch="main")Created new Icechunk repoOnce set up, the rest is the same
# Run the for loop
import time
from pathlib import Path
for i, url in enumerate(urls[:5]):
filename = Path(url).name
start = time.perf_counter()
print(f"Adding {filename}")
vds = open_virtual_dataset(
url=url,
parser=parser,
registry=registry,
loadable_variables=["time", "latitude", "longitude"],
decode_times=True,
).drop_vars(["nv", "ncrs", "crs"], errors="ignore")
if i == 0:
vds.vz.to_icechunk(session.store)
else:
vds.vz.to_icechunk(session.store, append_dim="time")
elapsed = time.perf_counter() - start
print(f"Finished {filename} in {elapsed:.2f} seconds")
snapshot_id = session.commit("5 days NDVI CDR Jan 2000")
print("Committed:", snapshot_id)Adding AVHRR-Land_v005_AVH13C1_NOAA-14_20000101_c20170623095628.nc
Finished AVHRR-Land_v005_AVH13C1_NOAA-14_20000101_c20170623095628.nc in 8.03 seconds
Adding AVHRR-Land_v005_AVH13C1_NOAA-14_20000102_c20170623101557.nc
Finished AVHRR-Land_v005_AVH13C1_NOAA-14_20000102_c20170623101557.nc in 6.04 seconds
Adding AVHRR-Land_v005_AVH13C1_NOAA-14_20000103_c20170623103338.nc
Finished AVHRR-Land_v005_AVH13C1_NOAA-14_20000103_c20170623103338.nc in 5.64 seconds
Adding AVHRR-Land_v005_AVH13C1_NOAA-14_20000104_c20170623105028.nc
Finished AVHRR-Land_v005_AVH13C1_NOAA-14_20000104_c20170623105028.nc in 6.30 seconds
Adding AVHRR-Land_v005_AVH13C1_NOAA-14_20000105_c20170623110559.nc
Finished AVHRR-Land_v005_AVH13C1_NOAA-14_20000105_c20170623110559.nc in 5.88 seconds
Committed: A59D4CBRS3XT6MHPGZ50# So about 24 hours to do all 40 years
# If done in series, not parallel
365*40*6/(60*60)24.333333333333332Public reading of our icechunk
Add these as instructions in for your dataset.
import icechunk
import xarray as xr
# -------------------------------------------------------------------
# 1. Authorize access to the original NOAA NetCDF chunks
# -------------------------------------------------------------------
# The Icechunk repo contains virtual chunk references back to a
# public NOAA S3 bucket.
credentials = icechunk.containers_credentials({
"s3://noaa-cdr-ndvi-pds/": icechunk.s3_credentials(anonymous=True)
})
# -------------------------------------------------------------------
# 2. Tell Icechunk where virtual chunks are allowed to come from
# -------------------------------------------------------------------
config = icechunk.RepositoryConfig.default()
config.set_virtual_chunk_container(
icechunk.VirtualChunkContainer(
url_prefix="s3://noaa-cdr-ndvi-pds/",
store=icechunk.s3_store(region="us-east-1", anonymous=True),
),
)
# -------------------------------------------------------------------
# 3. Point to the public Icechunk repo on Source Cooperative
# -------------------------------------------------------------------
# This is the location of the Icechunk repository itself.
storage = icechunk.s3_storage(
bucket="us-west-2.opendata.source.coop",
prefix="eeholmes/chlaz/icechunk",
region="us-west-2",
anonymous=True,
)
# -------------------------------------------------------------------
# 4. Open the Icechunk repo and read it with xarray
# -------------------------------------------------------------------
repo = icechunk.Repository.open(
storage,
config=config,
authorize_virtual_chunk_access=credentials,
)
session = repo.readonly_session(branch="main")
ds = xr.open_zarr(
session.store,
consolidated=False,
chunks=None,
)
ds<xarray.Dataset> Size: 2GB
Dimensions: (time: 5, latitude: 3600, longitude: 7200, nv: 2)
Coordinates:
* time (time) datetime64[ns] 40B 2000-01-01 2000-01-02 ... 2000-01-05
* latitude (latitude) float32 14kB 89.97 89.93 89.88 ... -89.93 -89.97
* longitude (longitude) float32 29kB -180.0 -179.9 -179.9 ... 179.9 180.0
Dimensions without coordinates: nv
Data variables:
NDVI (time, latitude, longitude) float64 1GB ...
TIMEOFDAY (time, latitude, longitude) datetime64[ns] 1GB ...
lon_bnds (longitude, nv) float32 58kB ...
QA (time, latitude, longitude) int16 259MB ...
lat_bnds (latitude, nv) float32 29kB ...
Attributes: (12/48)
title: Normalized Difference Vegetation ...
institution: NASA/GSFC/SED/ESD/HBSL/TIS/MODIS-...
Conventions: CF-1.6, ACDD-1.3
standard_name_vocabulary: CF Standard Name Table (v25, 05 J...
naming_authority: gov.noaa.ncei
license: See the Use Agreement for this CD...
... ...
PercentValidDaytimeData: 32.01
PercentValidDaytimeLand: 32.01
PercentValidClearDaytimeLand: 3.14
PercentValidDaytimeLandInCloudShadow: 1.04
PercentValidClearDaytimeWater: 0.00
PercentValidDaytimeWaterInCloudShadow: 0.00We can vizualize Icechunks in public stores
Javascript libraries zarrita and icechunk-js allow us to create visualizations of public Zarr stores.
https://eeholmes.github.io/gridlook/#https://data.source.coop/eeholmes/chlaz/icechunk
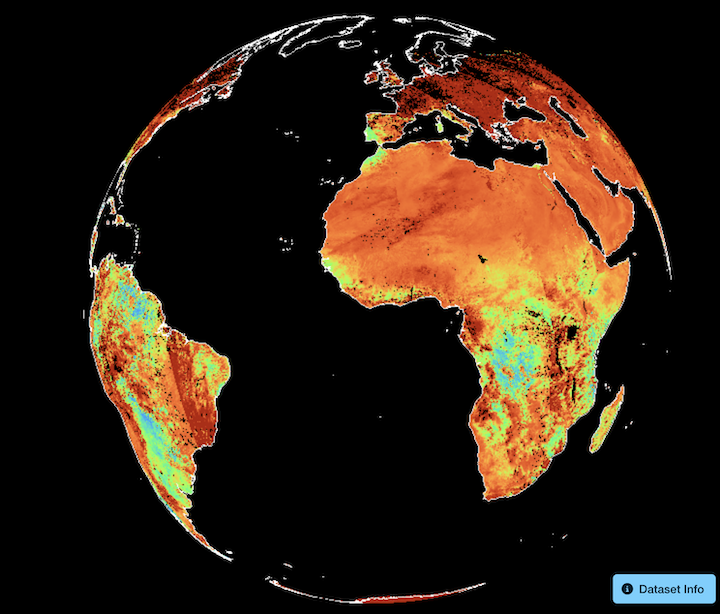
Make a plot with hvplot
import hvplot.xarray
ds["NDVI"].isel(time=0).hvplot.quadmesh(
rasterize=True,
x="longitude",
y="latitude",
title="AVHRR NDVI — 2000-01-01",
width=800,
height=400,
xlim=(-180, 180),
ylim=(-90, 90),
cmap = "turbo_r"
)A non-memory efficient plot
# This would require a lot of RAM
ds["NDVI"].isel(time=0).plot(
x="longitude",
y="latitude",
figsize=(10, 4)
)