# Uncomment this line and run if you are in Colab; leave in the !. That is part of the cmd
# !pip install zarr gcsfs --quietSimple Machine-Learning: CNN, UNet and Boosted Regression
Author: Eli Holmes (NOAA)
Last updated: March 20, 2026
📘 Learning Objectives
- Understand the basics of prediction
- Learn the format that your data should be in
- Learn to fit a CNN and Boosted Regression Tree
- Evaluate fit
- Make predictions with your model
Important notes for this tutorial
Data must be able to be loaded into memory
This notebook creates the training data as NumPy arrays. The data needs to be able to be loaded fully into memory. We will discuss working with larger than memory data in the advanced tutorials.
Run this with GPU
This notebook is slow with CPU. You can run in Colab if you don’t have GPU access. Click the “Open in Colab” button above. To get GPU in Colab, go to Edit > Notebook Settings and select GPU. Then uncomment the !pip line below to install the needed libraries. For the JupyterHub, you might not have the option to select GPU.
This notebook requires tensorflow
Colab has tensorflow installed by default. For the JupyterHub, you need to select an image with tensorflow. We used the image quay.io/pangeo/ml-notebook:2025.05.22 for running the notebook.
The functions are in a separate file
The Python functions for doing tasks, like prepping the data and plotting, are in a separate file ml_utils.py and the functions are imported with import ml_utils as mu. You will need to run the import code to have access to the functions.
Summary
In this tutorial we will predict a variable (chl) using predictor variables, in this case SST, salinity, and season.
\[ \hat{y} \sim f(sst, so, season, location) \]
We will compare two classic machine-learning algorithms for prediction: 2-dimensional convolutional neural networks and boosted regression trees.
How are they similar?
Both are non-linear: they can learn complicated non-linear relationships like “very high CHL only occurs when SST is low and it’s winter and we are above a certain latitude threshold.” Both can handle complex interactions between variables (SST × salinity × season × location). Both are strong baseline methods for prediction tasks like ours.
How are they different?
Input shape: Boosted regression trees see individuals pixels. They ignore the neighboring pixels, unless we add them as extra predictor variables. 2D CNNs look at a small area around each pixel. They use the neighborhood to detect patterns like lines, blobs, and gradients.
What they learn: Trees learn a big collection of if-else rules that split the response variable space. CNNs learn spatial filters (little square spatial weightings) that slide over the map to detect shapes and textures (e.g. sharp gradients).
Spatial awareness: Trees have no built-in spatial structure; “location” is just another number. CNNs are explicitly designed for using spatial structure and patterns for the prediction.
Interpretability: Trees (especially boosted trees with feature importance / partial dependence) are usually easier to interpret. CNNs are more of a black box; they can capture richer patterns but are harder to “read”.
Overview of the modeling steps
- Load data
- Prepare training, test, and validation data. Normalize the training data and deal with NAs in the data.
- Set up model
- Fit model
- Make predictions
Variables in the model
| Feature | Spatial Variation | Temporal Variation | Notes |
|---|---|---|---|
sst, so |
✅ Varies by lat/lon | ✅ Varies by time | Numeric, normalize |
sin_time, cos_time |
❌ Same across lat/lon | ✅ Varies by time | Cyclical, do not normalize |
x_geo,y_geo, z_geo |
✅ Varies by lat/lon | ❌ Static | -1 to 1, do not normalize |
ocean_mask |
✅ Varies by lat/lon | ❌ Static | Binary (0=land, 1=ocean), do not normalize |
cloud_mask |
✅ Varies by lat/lon | ✅ Varies by time | Binary (0=land, 1=ocean), do not normalize |
y (log CHL) |
✅ Varies by lat/lon | ✅ Varies by time | Numeric, maybe normalize |
sstandso: These are our core predictor variables. We normalize these to mean 0 and s.d. of 1 so they are on the same scale.sin_timeandcos_time: These introduce seasonality into our model. The models can learn seasonally dependent patterns, e.g., chlorophyll blooms in spring. Thesin_timeandcos_timefeatures use cyclical encoding (sine/cosine). Normalizing these features (e.g., to mean 0, std 1) would distort their circular geometry and defeat their intended purpose.x_geo,y_geo, andz_geo: This is a dimensionless geometric encoding of location on the globe that is -1 to 1. This works better than lat/lon for machine-learning tasks. Including these location variables allows the model to learn location specific relationships.ocean_mask,cloud_mask: This tells the model which pixels are land (0) vs ocean (1) and cloud (0) versus valid (1). For the CNN, the mask is used in a custom loss function which helps avoid learning patterns over invalid/land/cloud areas. The ocean mask is also used as a predictor variable to help it learn the effect of coastlines.y(response): The model trains on this. For our model it is logged CHL and it is roughly centered near 0. We need to evaluate whether our response has areas with much much higher variance than other areas. If so, we need to do some spatial normalization so our model doesn’t only learn the high variance areas.
Note, neither bathymetry nor distance from coast improved the model by any appreciable amount over the model we use here. SST (upwelling signal) and salinity (river outflow signal) are highly correlated with chlorophyll in this region with strong seasonal patterns. Including the ocean mask and location in the fitting allows it to learn the coastal patterns.
Dealing with NaNs
In our application, NaNs in y (in our case CHL) appear over land and when obscured by clouds. NaNs in our predictor variables are less common, but can happen. Algorithms for boosted regression trees can filter out any pixels that have NaNs in the response and predictor variables so we just have to make sure that missing values, or areas to ignore like land are coded as NaN. But for CNNs dealing with NaNs is harder because the models do not allow any NaNs in the response or predictor variables. For y, the problem comes when the training algorithm calculates the training (and validation) loss. Those NaNs in y will lead to NaN in y - y_pred, the loss returns NaN and training immediately breaks down. We therefore use a custom masked loss function that multiplies the error by an ocean/valid-pixel mask and normalizes by the number of valid pixels, effectively excluding land/cloudy pixels from the loss and validation metrics.
NaNs/Infs in the predictor variables will prevent the model from creating a prediction at all. Therefore NaNs (or Infs) in our predictor variables must be replaced or imputed. In this notebook, we replace these with the pixel median from the pixels that are not missing. In order to guard against training on too much imputed data, days with more than 5% missing pixels in the predictor variables are removed.
Modifying the notebook to model your own data
You will need the following:
- Data: an xarray Dataset with your response variable and predictor variables.
num_var: the variables which will be normalizedcat_var: the variables which will be left as ismask: The model will not be trained on the data under the mask- response variable (
y) should have NaNs for missing values. Do not replace missing values with anything. - functions: in
ml_utils.py
Variables can be 2D (not time-varying) or 3D (time-varying). They can be numerical (will be normalized) or categorical (will not be normalized). Note, categorical can be numerical. Difference is what will be normalized and what will not.
Load the libraries
- core data handling and plotting libraries
- tensorflow libraries
- our custom functions in
ml_utils.py
# --- Core data handling and plotting libraries ---
import xarray as xr # for working with labeled multi-dimensional arrays
import numpy as np # for numerical operations on arrays
import matplotlib.pyplot as plt # for creating plots# --- TensorFlow libraries ---
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # suppress TensorFlow log spam (0=all, 3=only errors)
import tensorflow as tf # main deep learning framework
# --- Keras (part of TensorFlow): building and training neural networks ---
from keras.models import Sequential # lets us stack layers in a simple linear model
from keras.layers import Conv2D # 2D convolution layer — finds spatial patterns in image-like data
from keras.layers import BatchNormalization # stabilizes and speeds up training by normalizing activations
from keras.layers import Dropout # randomly "drops" neurons during training to reduce overfitting
from keras.callbacks import EarlyStopping # stops training early if validation loss doesn't improve# --- Custom python functions ---
# this requires that tensorflow and keras are available
import os, importlib
# Looks to see if you have the file already and if not, downloads from GitHub
if not os.path.exists("ml_utils.py"):
!wget -q https://raw.githubusercontent.com/fish-pace/2025-tutorials/main/ml_utils.py
import ml_utils as mu
importlib.reload(mu)<module 'ml_utils' from '/home/jovyan/2025-tutorials/ml_utils.py'>Prepare the Indian Ocean Dataset
This is a dataset for the Indian Ocean with a variety of variables, including chlorophyll which will will try to predict using SST, salinity, location and season. The data are in Google Object Storage as a chunked Zarr file. It has files that are chunks of 100 days of data. When we go to get data we will get these files. How we load our data will determine if our xarray dataset “knows” about the chunks and this will make a big difference to speed and memory usage. xarray.open_dataset will not know the chunking while xarray.open_zarr will.
We need our lat/lon number of pixels to be even
This is a requirement for the U-Net model we will fit.
# Load the Indian Ocean Dataset
# Note use open_zarr instead of open_dataset to preserve the chunking
data_full = xr.open_zarr(
"gcs://nmfs_odp_nwfsc/CB/mind_the_chl_gap/IO.zarr",
storage_options={"token": "anon"},
consolidated=True
)
# slice to a smaller lat/lon segment
data_full = data_full.sel(lat=slice(35, -5), lon=slice(45,90))
# Make lat/lon lengths even for our simple U-Net model
if data_full.sizes["lat"] % 2 == 1: data_full = data_full.isel(lat=slice(0, -1)) # drop last lat
if data_full.sizes["lon"] % 2 == 1: data_full = data_full.isel(lon=slice(0, -1)) # drop last lon
# subset out predictors, response and land mask
pred_var = ["sst", "so"]
resp_var = "CHL_cmes-gapfree"
land_mask = "CHL_cmes-land"
dataset = data_full[pred_var + [resp_var, land_mask]]
dataset = dataset.rename({resp_var: "y", land_mask: "land_mask"})
# IMPORTANT! log our response so it is symmetric (Normal-ish)
dataset["y"] = np.log(dataset["y"])
# remove years with no response (y), sst or salinity data; these will be all NaN
vars_to_check = ["y", "so", "sst"]
drop = dataset[vars_to_check].to_array().isnull().all(["lat", "lon"]).any("variable")
dataset = dataset.sel(time=~drop)
# Make ocean mask
# Mark where SST (sea surface temperature) is always missing; these are likely lakes
dataset["land_mask"] = dataset["land_mask"] == 0 # make ocean 1 instead of land
invalid_ocean = np.isnan(dataset["sst"]).all(dim="time")
dataset["land_mask"] = dataset["land_mask"].where(~invalid_ocean, other=False)
dataset = dataset.rename({"land_mask": "ocean_mask"})
# Add location and seasonality variables
dataset = mu.add_spherical_coords(dataset) # add lat/lon variables to dataset
dataset = mu.add_seasonal_time_features(dataset)
# fix chunking to be consistent
dataset = dataset.chunk({'time': 100, 'lat': -1, 'lon': -1})
dataset<xarray.Dataset> Size: 5GB
Dimensions: (time: 8475, lat: 148, lon: 180)
Coordinates:
* lat (lat) float32 592B 32.0 31.75 31.5 31.25 ... -4.25 -4.5 -4.75
* lon (lon) float32 720B 45.0 45.25 45.5 45.75 ... 89.25 89.5 89.75
* time (time) datetime64[ns] 68kB 1997-10-01 1997-10-02 ... 2020-12-31
Data variables:
sst (time, lat, lon) float32 903MB dask.array<chunksize=(100, 148, 180), meta=np.ndarray>
so (time, lat, lon) float32 903MB dask.array<chunksize=(100, 148, 180), meta=np.ndarray>
y (time, lat, lon) float32 903MB dask.array<chunksize=(100, 148, 180), meta=np.ndarray>
ocean_mask (lat, lon) bool 27kB dask.array<chunksize=(148, 180), meta=np.ndarray>
x_geo (lat, lon) float32 107kB dask.array<chunksize=(148, 180), meta=np.ndarray>
y_geo (lat, lon) float32 107kB dask.array<chunksize=(148, 180), meta=np.ndarray>
z_geo (lat, lon) float32 107kB dask.array<chunksize=(148, 180), meta=np.ndarray>
sin_time (time, lat, lon) float32 903MB dask.array<chunksize=(100, 148, 180), meta=np.ndarray>
cos_time (time, lat, lon) float32 903MB dask.array<chunksize=(100, 148, 180), meta=np.ndarray>
Attributes: (12/92)
Conventions: CF-1.8, ACDD-1.3
DPM_reference: GC-UD-ACRI-PUG
IODD_reference: GC-UD-ACRI-PUG
acknowledgement: The Licensees will ensure that original ...
citation: The Licensees will ensure that original ...
cmems_product_id: OCEANCOLOUR_GLO_BGC_L3_MY_009_103
... ...
time_coverage_end: 2024-04-18T02:58:23Z
time_coverage_resolution: P1D
time_coverage_start: 2024-04-16T21:12:05Z
title: cmems_obs-oc_glo_bgc-plankton_my_l3-mult...
westernmost_longitude: -180.0
westernmost_valid_longitude: -180.0Process the data for training and testing
The time_series_split function in ml_utils.py (loaded as mu) will do the following.
- Get the year(s) we want for training
- Remove the days with too many NaNs (> 10 percent) in response or explanatory variables
- Split data randomly into train, validate, and test pools
- Normalize the numerical predictor variables (SST and salinity)
- Replace NaNs in our numerical predictor variables with the pixel mean in training data.
- Return stacked Numpy arrays
We need to normalize (mean zero, variance of 1) our numerical predictor variables but we need to compute the normalization metrics (X_mean and X_std) from the training data only. Otherwise we would have “data leakage”; information from the data we are predicting (not using for training) is used in testing or validation.
This function is stored in model_utils.py and loaded with import model_utils as mu. If you are running this notebook in your own directory, you will need to download model_utils.py into the same directory as where you have this notebook.
help(mu.time_series_split)Help on function time_series_split in module ml_utils:
time_series_split(data: xarray.core.dataset.Dataset, num_var, cat_var=None, mask='ocean_mask', split_ratio=(0.7, 0.2, 0.1), seed=42, X_mean=None, X_std=None, y_var='y', years=None, cast_float32=True, contiguous_splits=False, return_full=False, nan_max_frac_y=0.5, nan_max_frac_v=0.05, add_missingness=False, verbose=False)
Pure-NumPy splitter/normalizer for xarray Dataset (NumPy-backed).
Splits time indices randomly into train/val/test.
Normalizes numerical variables only, using either provided or training-set mean/std.
Replaces NaNs with 0s.
Removes days with too many NaNs (>
Parameters:
data: xarray dataset with 'time' dimension
years: year(s) to use for training
num_var: list of numerical variable names (to normalize)
cat_var: list of categorical variable names (no normalization)
y_var: name of response variable in data.
mask: name of the mask in the data. 0 = ignore; 1 = use; can be static or one for each time step (y)
split_ratio: tuple (train, val, test), must sum to 1.0
seed: random seed
nan_max_frac_y: maximum percent missing values for response
nan_max_frac_v: maximum percent missing values for explanatory variables
X_mean, X_std: optional mean/std arrays for num_var only (shape = [n_num_vars])
cast_float32 : If True, cast outputs to float32 (good for TF)
verbose: print out info
return_full: return X and y
contiguous_splits: versus random splits
Returns:
X, y: full input and response arrays (NumPy arrays)
X_train, y_train, X_val, y_val, X_test, y_test: split data X_mean, X_std: mean and std used for normalization
If return_full=False, X and y are None.
# Our predictor variables; numerical variables and categorical variables
num_var = ['sst','so']
cat_var = ['ocean_mask','sin_time','cos_time','x_geo', 'y_geo', 'z_geo']
# Our time_series_split function needs the dataset to be loaded into memory
dataset.load();# Train on 3 years in different decades
X, y, X_train, y_train, X_val, y_val, X_test, y_test, X_mean, X_std = \
mu.time_series_split(dataset,
num_var, cat_var=cat_var,
split_ratio=(0.7,0.2,0.1),
years=[2000, 2010, 2020],
nan_max_frac_y=0.5, # max y that can be NaN
nan_max_frac_v=0.05); # max predictors vars that can be imputedCreate the CNN models
A simple 2 layer 2D CNN to create pixel predictions. This is super simple and we don’t use Batch Normalization or Dropout. Those are standard techniques to improve fitting but did not seem to have much effect for this simple CNN.
from keras.models import Sequential
from keras.layers import Input, Conv2D
def tiny_CNN(input_shape):
"""
Create a simple 2-layer CNN model for gridded data to predict single output (log-CHL).
Layer 1 — learns 64 fine-scale 3x3 spatial features.
Layer 2 — expands context to 5x5; combines fine features into larger structures.
Activation "relu" provides non-linearity relationship between variables and chl.
Output combines all the previous layer’s features into a CHL estimate at each pixel.
1 response (chl value) — hence, 1 prediction pixel = 1 filter. Activation is linear since predicting
a real continuous variable (log CHL)
"""
model = Sequential()
model.add(Input(shape=input_shape)) # define the input dimensions for the CNN
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu')) # Layer 1
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu')) # Layer 2
model.add(Conv2D(filters=1, kernel_size=(3, 3), padding='same', activation='linear')) # Output
return modelfrom keras.models import Model
from keras.layers import Input, Conv2D
def tiny_cnn(input_shape):
"""
Create a simple 2-layer CNN model for gridded data to predict single output (log-CHL).
Layer 1 — learns 64 fine-scale 3x3 spatial features.
Layer 2 — expands context to 5x5; combines fine features into larger structures.
Activation "relu" provides non-linearity relationship between variables and chl.
Output combines all the previous layer’s features into a CHL estimate at each pixel.
1 response (chl value) — hence, 1 prediction pixel = 1 filter. Activation is linear since predicting
a real continuous variable (log CHL)
"""
inputs = Input(shape=input_shape) # define the input dimensions for the CNN
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu')(inputs) # Layer 1
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu')(x) # Layer 2
outputs = Conv2D(filters=1, kernel_size=(3, 3), padding='same', activation='linear')(x) # Output
model = Model(inputs=inputs, outputs=outputs, name="tiny_cnn")
return modelCreate a custom loss function
The y have NaNs (over land and under clouds). We need to mask these out to calculate the training and validation loss. That way we do not train on NAs in y.
import tensorflow as tf
import numpy as np
# Build once, BEFORE compiling the model
floatx = tf.keras.backend.floatx() # e.g., 'float32' or 'float16' if using mixed precision
ocean_mask_np = dataset['ocean_mask'].values.astype(np.float32) # (H, W)
OCEAN_MASK = tf.constant(ocean_mask_np)[tf.newaxis, ..., tf.newaxis] # (1, H, W, 1)
ocean_bool = tf.greater(OCEAN_MASK, 0.5)
@tf.function
def masked_mae(y_true, y_pred):
# Ensure shape (B, H, W, 1)
if y_true.shape.rank == 3:
y_true = y_true[..., tf.newaxis]
if y_pred.shape.rank == 3:
y_pred = y_pred[..., tf.newaxis]
# Valid where labels are finite (not = NaN)
valid = tf.math.is_finite(y_true) # (B, H, W, 1), bool
mask_bool = tf.logical_and(valid, ocean_bool)
mask = tf.cast(mask_bool, y_true.dtype)
mask = tf.stop_gradient(mask)
# Safe labels for diff (avoid any NaNs in subtraction)
y_true_safe = tf.where(mask_bool, y_true, tf.zeros_like(y_true))
diff = tf.abs(y_true_safe - y_pred) * mask
denom = tf.reduce_sum(mask) + tf.keras.backend.epsilon()
# Safe divide: if a batch has no valid ocean pixels, return 0.0 instead of NaN.
return tf.where(denom > 0, tf.reduce_sum(diff) / denom, tf.zeros((), y_true.dtype))Train the model
We will train for 50 epochs. From plotting out the fitting, I know that the validation and training errors level off around 50 epochs. Compile the model with Adam optimizer which is a standard choice. We use the custom loss function masked_mae because the standard one would break with NaNs in our y. Batch size is the number of days of data used in each fitting round. You can make it bigger but it would need more memory.
# Create the model using the correct input shape
cnn_model = tiny_cnn(X_train.shape[1:])
# Compile the model
cnn_model.compile(
optimizer='adam',
loss=masked_mae
)
# Train the CNN model
cnn_history = cnn_model.fit(
X_train, y_train,
batch_size=8,
epochs=50,
validation_data=(X_val, y_val)
)Epoch 1/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 9s 48ms/step - loss: 0.6982 - val_loss: 0.3342 Epoch 2/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.3109 - val_loss: 0.3010 Epoch 3/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2945 - val_loss: 0.2872 Epoch 4/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2897 - val_loss: 0.2769 Epoch 5/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2801 - val_loss: 0.2720 Epoch 6/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2704 - val_loss: 0.2663 Epoch 7/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2684 - val_loss: 0.2632 Epoch 8/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2736 - val_loss: 0.2607 Epoch 9/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2640 - val_loss: 0.2622 Epoch 10/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2636 - val_loss: 0.2612 Epoch 11/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2653 - val_loss: 0.2547 Epoch 12/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2600 - val_loss: 0.2667 Epoch 13/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2583 - val_loss: 0.2564 Epoch 14/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2544 - val_loss: 0.2590 Epoch 15/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2566 - val_loss: 0.2517 Epoch 16/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2527 - val_loss: 0.2529 Epoch 17/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2566 - val_loss: 0.2668 Epoch 18/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2588 - val_loss: 0.2499 Epoch 19/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 14ms/step - loss: 0.2524 - val_loss: 0.2547 Epoch 20/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2502 - val_loss: 0.2505 Epoch 21/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2495 - val_loss: 0.2489 Epoch 22/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2524 - val_loss: 0.2490 Epoch 23/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2516 - val_loss: 0.2456 Epoch 24/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2498 - val_loss: 0.2543 Epoch 25/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2456 - val_loss: 0.2546 Epoch 26/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2502 - val_loss: 0.2459 Epoch 27/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2479 - val_loss: 0.2426 Epoch 28/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 15ms/step - loss: 0.2463 - val_loss: 0.2555 Epoch 29/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2489 - val_loss: 0.2517 Epoch 30/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2468 - val_loss: 0.2743 Epoch 31/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 14ms/step - loss: 0.2549 - val_loss: 0.2463 Epoch 32/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2446 - val_loss: 0.2470 Epoch 33/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2444 - val_loss: 0.2476 Epoch 34/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2428 - val_loss: 0.2580 Epoch 35/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2441 - val_loss: 0.2587 Epoch 36/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2488 - val_loss: 0.2447 Epoch 37/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2439 - val_loss: 0.2522 Epoch 38/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2422 - val_loss: 0.2468 Epoch 39/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2447 - val_loss: 0.2427 Epoch 40/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 14ms/step - loss: 0.2416 - val_loss: 0.2402 Epoch 41/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2421 - val_loss: 0.2408 Epoch 42/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2379 - val_loss: 0.2518 Epoch 43/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2415 - val_loss: 0.2456 Epoch 44/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2425 - val_loss: 0.2725 Epoch 45/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2475 - val_loss: 0.2418 Epoch 46/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2408 - val_loss: 0.2450 Epoch 47/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2389 - val_loss: 0.2448 Epoch 48/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2396 - val_loss: 0.2439 Epoch 49/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2423 - val_loss: 0.2389 Epoch 50/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - loss: 0.2402 - val_loss: 0.2373
Save the model for loading later
# Save
meta = {"num_var": num_var, "cat_var": cat_var, "input_shape": list(X_train.shape[1:])}
mu.save_cnn_bundle("artifacts/cnn_bundle.zip", cnn_model, X_mean, X_std, meta)'artifacts/cnn_bundle.zip'# Load later (in a fresh session)
from model_utils import load_cnn_bundle
cnn_model, X_mean, X_std, meta = load_cnn_bundle("artifacts/cnn_bundle.zip", compile=False)Plot training & validation loss values
plt.figure(figsize=(10, 6))
plt.plot(cnn_history.history['loss'], label='Train Loss')
plt.plot(cnn_history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
Prepare test dataset
# Evaluate the model on the test dataset
test_loss = cnn_model.evaluate(X_test, y_test)
print(f"Test Loss: {test_loss}")4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 0.2376 Test Loss: 0.2392425239086151
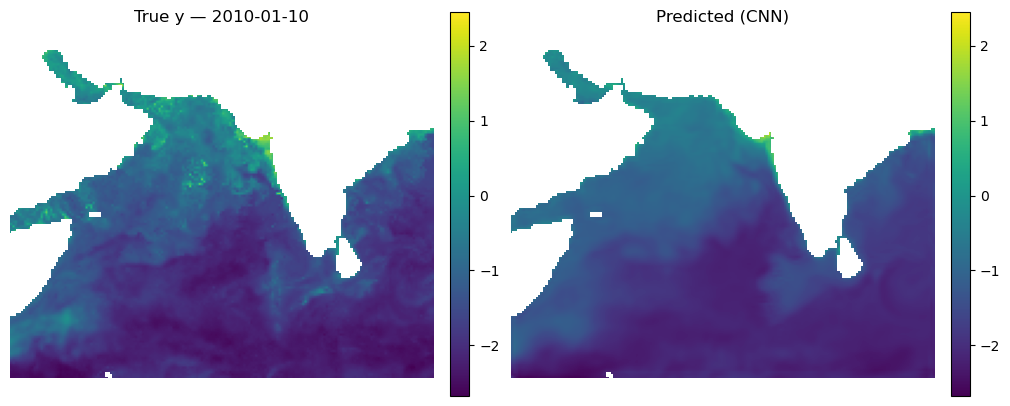
Make some maps of our predictions
_ = mu.predict_and_plot_date(
data_xr=dataset,
date="2010-01-10",
model=cnn_model,
num_var=num_var,
cat_var=cat_var,
X_mean=X_mean, X_std=X_std,
model_type="cnn",
use_percentiles=False
)
Let’s look at all the months
This is a function that takes our model, the normalizing X_mean and X_std, the year to use and then makes plots of true versus predicted for the first available day each month. We need to use X_mean and X_std from our training data. This was returned by time_series_split() above.
mu.plot_true_vs_predicted_year_multi(
dataset, "2001", [cnn_model], X_mean, X_std,
num_var, cat_var, y_var="y", day=10,
model_types=["cnn"],
model_names=["CNN"])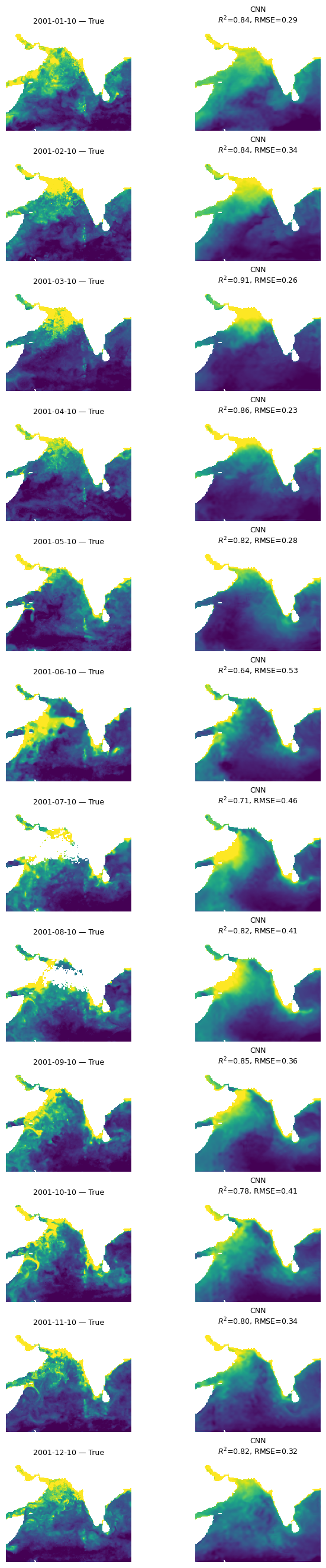
Look at fit metrics over years
Here I compute the metrics for 4 days in each month and average together. The metrics are R2, bias, mean abs error and SSIM. SSIM/MS-SSIM is a metric for images. It runs from (about) 0 to 1. Higher is better; 1.0 = identical. Rough, practical bands:
- ≥ 0.95 — near-indistinguishable (often called “visually lossless” in imaging)
- 0.90–0.95 — very good structural agreement
- 0.80–0.90 — clearly similar patterns, some blur/offset/contrast differences
- 0.60–0.80 — moderate; big structures align but details differ
- < 0.60 — poor structural match
%%time
mu.plot_4metric_by_month(dataset, ['1999', '2004', '2009', '2014', '2020'],
cnn_model, X_mean, X_std,
num_var, cat_var,
training_year="2020")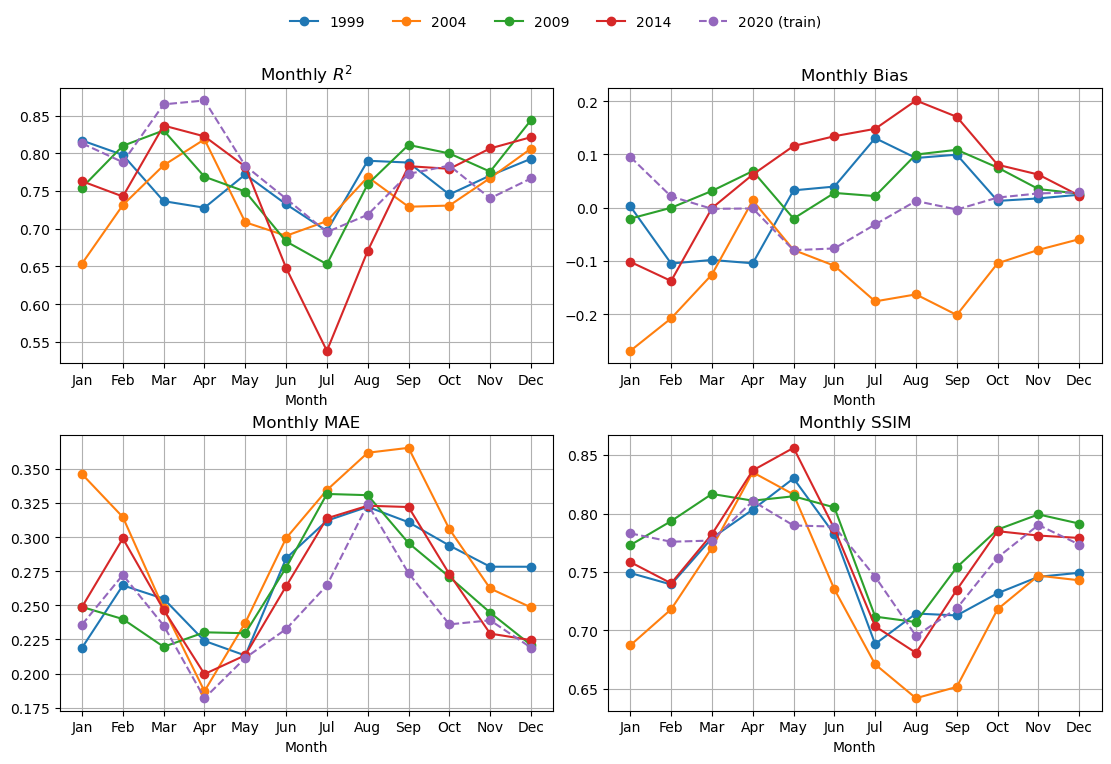
CPU times: user 8.69 s, sys: 231 ms, total: 8.92 s
Wall time: 8.9 sCompare to a BRT
We will use exactly the same explanatory variables. The main difference is that the BRT does not learn local features, like fronts and edges. On the otherhand, it doesn’t have the CNNs tendency to smudge out (average) local patterns.
# Fit the model
brt, brt_model = mu.train_brt_from_splits(
X_train, y_train, feature_names=num_var + cat_var,
grid_shape=(dataset.sizes['lat'], dataset.sizes['lon'])
)Look a fit metrics
This is slow for BRT.
%%time
mu.plot_4metric_by_month(dataset, ['1999', '2004', '2009', '2014', '2020'],
brt_model, X_mean, X_std,
num_var, cat_var,
training_year="2020",
model_type="brt")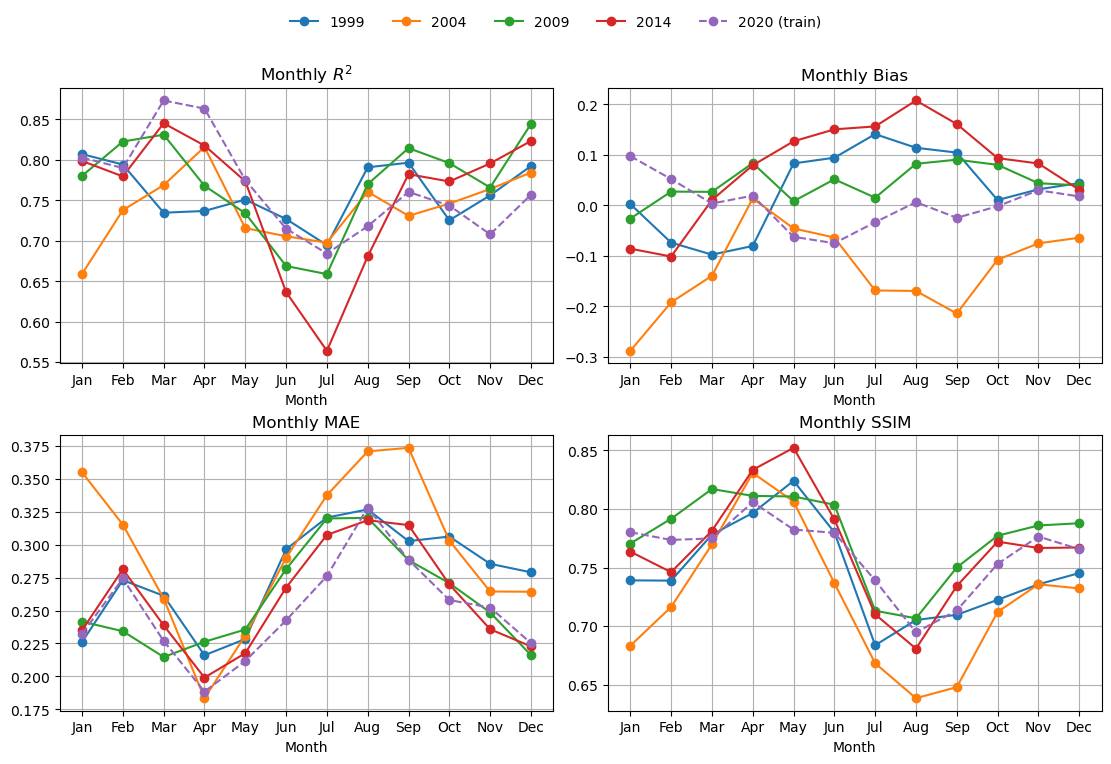
CPU times: user 3min, sys: 1.81 s, total: 3min 2s
Wall time: 1min 33sCompare BRT and CNN
mu.plot_true_vs_predicted_year_multi(
dataset, "2001", [cnn_model, brt_model], X_mean, X_std,
num_var, cat_var, y_var="y",
model_types=["cnn", "tabular"],
model_names=["CNN", "BRT"])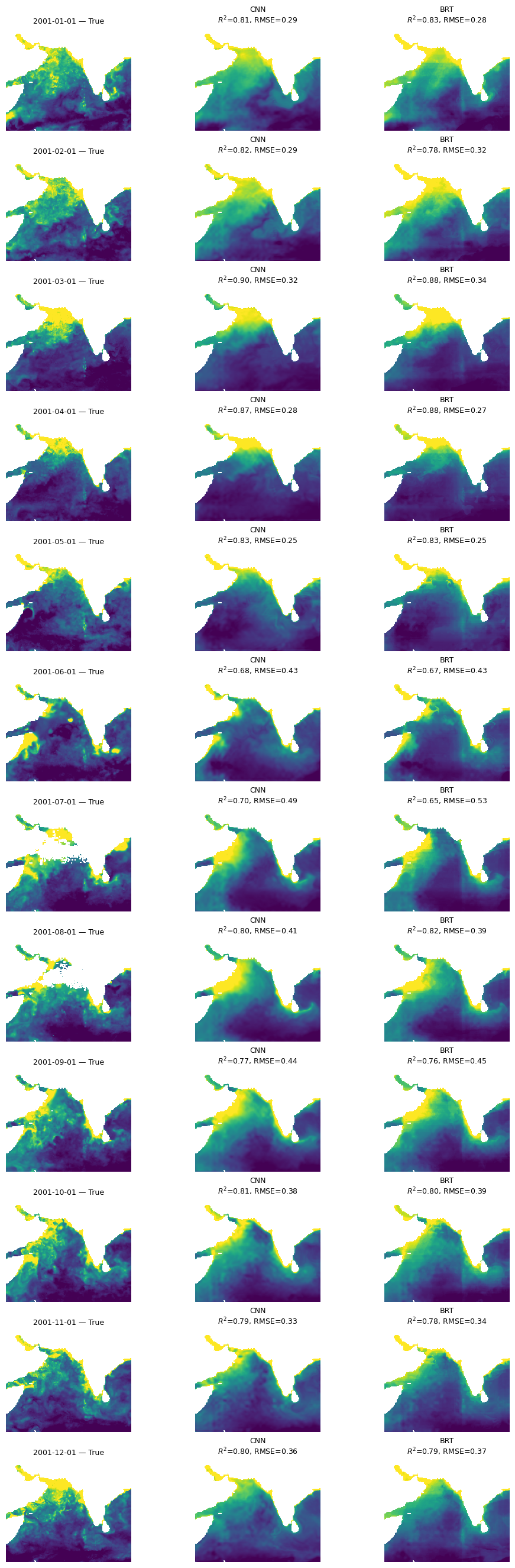
Try a UNet model
A feature of our CNN is that it is creating pixel estimates by averaging over an area so by design it will lose fine scale features. The BRT is a pixel by pixel estimate so it will retain fine-scale features but it cannot use the spatial information from neighboring pixels. Let’s try a U-Net that has a ‘decoder’ to upscale the prediction from the average back to fine-scale.
from keras.layers import (
Input, Conv2D, MaxPooling2D, UpSampling2D,
Concatenate
)
from keras.models import Model
def tiny_unet(input_shape):
inputs = Input(shape=input_shape)
# --- Encoder ---
# Level 1
c1 = Conv2D(32, (3, 3), activation='relu', padding='same')(inputs)
c1 = Conv2D(32, (3, 3), activation='relu', padding='same')(c1)
p1 = MaxPooling2D((2, 2))(c1) # H/2, W/2
# Level 2 (bottleneck-ish)
c2 = Conv2D(64, (3, 3), activation='relu', padding='same')(p1)
c2 = Conv2D(64, (3, 3), activation='relu', padding='same')(c2)
# --- Decoder ---
# Up to Level 1
u1 = UpSampling2D((2, 2))(c2) # back to H, W
u1 = Concatenate()([u1, c1]) # skip connection
c3 = Conv2D(32, (3, 3), activation='relu', padding='same')(u1)
c3 = Conv2D(32, (3, 3), activation='relu', padding='same')(c3)
# --- Output ---
outputs = Conv2D(1, (1, 1), activation='linear', padding='same')(c3)
model = Model(inputs, outputs, name="tiny_unet")
return model# Create the model using the correct input shape
unet_model = tiny_unet(X_train.shape[1:])
# Compile the model
unet_model.compile(
optimizer='adam',
loss=masked_mae
)
# Train the CNN model
unet_history = unet_model.fit(
X_train, y_train,
batch_size=8,
epochs=50,
validation_data=(X_val, y_val)
)Epoch 1/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 14s 87ms/step - loss: 0.6598 - val_loss: 0.3015 Epoch 2/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2981 - val_loss: 0.2819 Epoch 3/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2916 - val_loss: 0.2699 Epoch 4/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2661 - val_loss: 0.2706 Epoch 5/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2640 - val_loss: 0.2551 Epoch 6/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2736 - val_loss: 0.2478 Epoch 7/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2497 - val_loss: 0.2472 Epoch 8/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2516 - val_loss: 0.2501 Epoch 9/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2480 - val_loss: 0.2409 Epoch 10/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2471 - val_loss: 0.2397 Epoch 11/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2421 - val_loss: 0.2482 Epoch 12/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2377 - val_loss: 0.2366 Epoch 13/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2377 - val_loss: 0.2374 Epoch 14/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2389 - val_loss: 0.2316 Epoch 15/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2387 - val_loss: 0.2343 Epoch 16/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2319 - val_loss: 0.2426 Epoch 17/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2367 - val_loss: 0.2355 Epoch 18/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2319 - val_loss: 0.2296 Epoch 19/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2308 - val_loss: 0.2267 Epoch 20/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2298 - val_loss: 0.2300 Epoch 21/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2313 - val_loss: 0.2277 Epoch 22/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2253 - val_loss: 0.2354 Epoch 23/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2293 - val_loss: 0.2303 Epoch 24/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2272 - val_loss: 0.2234 Epoch 25/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2220 - val_loss: 0.2246 Epoch 26/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2262 - val_loss: 0.2281 Epoch 27/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2251 - val_loss: 0.2201 Epoch 28/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2265 - val_loss: 0.2233 Epoch 29/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2230 - val_loss: 0.2285 Epoch 30/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2211 - val_loss: 0.2216 Epoch 31/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2201 - val_loss: 0.2321 Epoch 32/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2202 - val_loss: 0.2235 Epoch 33/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2191 - val_loss: 0.2242 Epoch 34/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2209 - val_loss: 0.2223 Epoch 35/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2138 - val_loss: 0.2176 Epoch 36/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2189 - val_loss: 0.2167 Epoch 37/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2134 - val_loss: 0.2138 Epoch 38/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2165 - val_loss: 0.2138 Epoch 39/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2143 - val_loss: 0.2134 Epoch 40/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2125 - val_loss: 0.2145 Epoch 41/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2175 - val_loss: 0.2113 Epoch 42/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2153 - val_loss: 0.2171 Epoch 43/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2110 - val_loss: 0.2158 Epoch 44/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2075 - val_loss: 0.2138 Epoch 45/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2127 - val_loss: 0.2146 Epoch 46/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2100 - val_loss: 0.2132 Epoch 47/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 31ms/step - loss: 0.2148 - val_loss: 0.2158 Epoch 48/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2103 - val_loss: 0.2108 Epoch 49/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2080 - val_loss: 0.2160 Epoch 50/50 96/96 ━━━━━━━━━━━━━━━━━━━━ 3s 32ms/step - loss: 0.2099 - val_loss: 0.2099
mu.plot_true_vs_predicted_year_multi(
dataset, "2001", [cnn_model, unet_model], X_mean, X_std,
num_var, cat_var, y_var="y",
model_types=["cnn", "cnn"],
model_names=["CNN", "UNet"])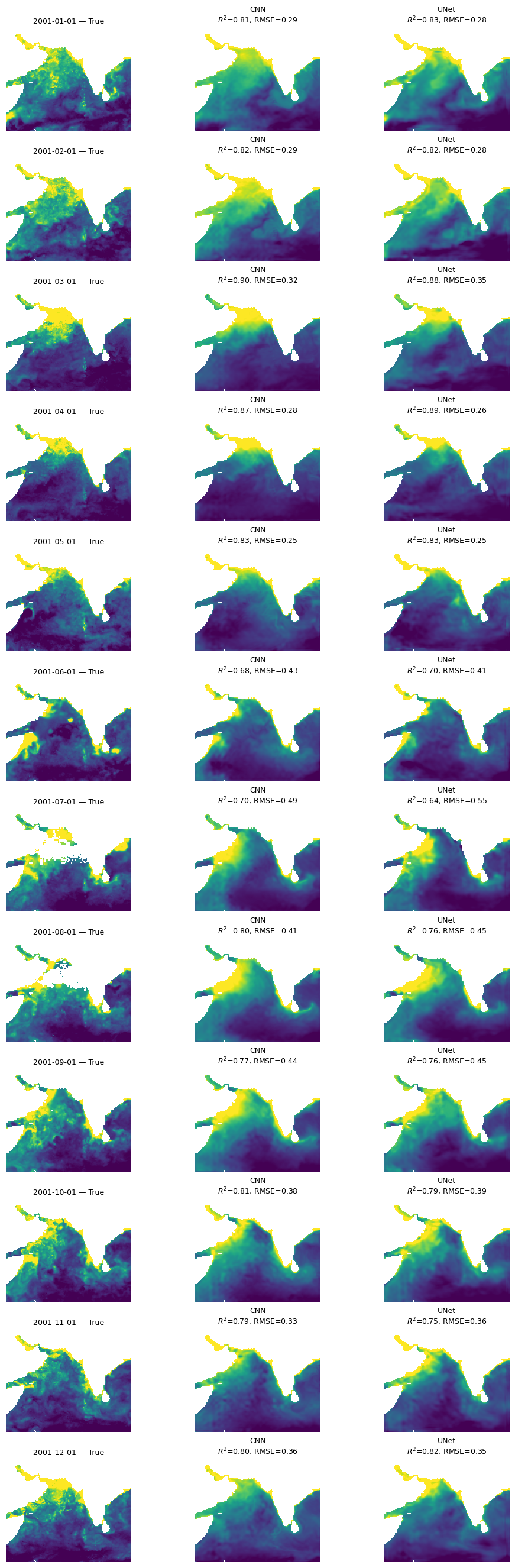
Summary
All three models are doing “doing” ok and doing fairly similarly. The CNN models (CNN and UNet) are smoother and do not have the banding issues that we see in the BRT. Also performances shows big variation by season and struggles to fit even our training data in the summer monsoon.
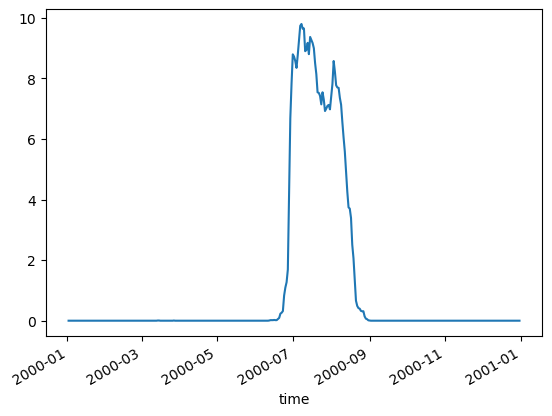
%%time
# CNN example
daily, monthly = mu.evaluate_year_batched(
dataset, 2000, cnn_model, X_mean, X_std,
num_var=num_var, cat_var=cat_var,
model_type='cnn', batch_size=16
)
# Plot daily R2 for 2000
daily['r2'].plot(marker='o', label='CNN');
plt.legend(); plt.title(" R² (2000)"); plt.show()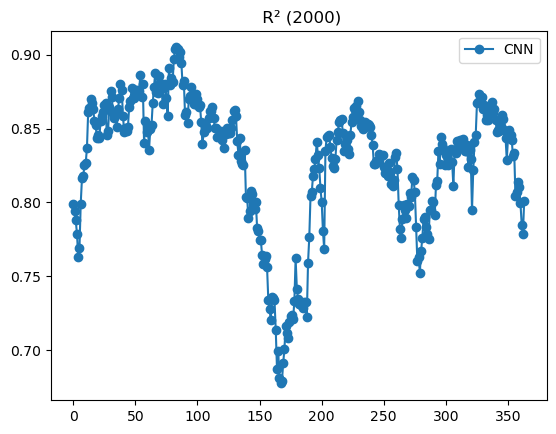
CPU times: user 7.88 s, sys: 22.9 ms, total: 7.91 s
Wall time: 7.88 sIt is true that most of the missing data in our CHL happens during the summer monsoon. We are using a gap-filled CHL product but their algorithm does not fill in pixels if those pixels never had a CHL observation over a decade. This does happen in this region. This means that certain days in July and August always have the same pixels missing. This probably causes odd behavior in those months.
mu.pct_missing_by_day_year(dataset, 2000).plot()