Intro the Cloud
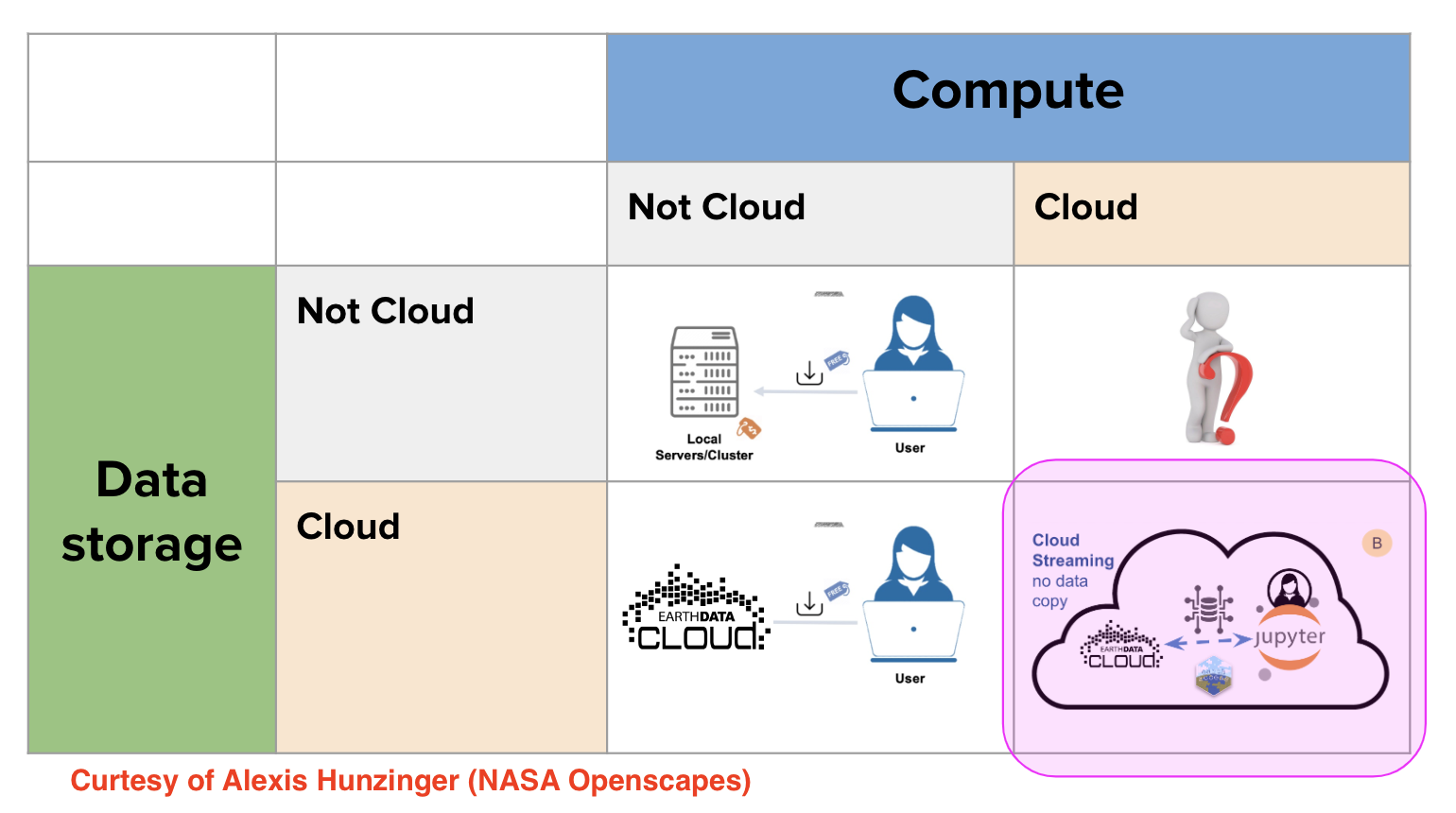 Today we are working with a JupyterHub in Azure, while the data we are accessing is on AWS us-west-2. This means we cannot really do the lower right option of ‘cloud native’ computing. If our JupyterHub were on AWS us-west-2, then we could direct connect to the S3 buckets and it would be as if we had downloaded the data. We can effectively “attach” a cloud drive with petabytes of data to our virtual machine.
Today we are working with a JupyterHub in Azure, while the data we are accessing is on AWS us-west-2. This means we cannot really do the lower right option of ‘cloud native’ computing. If our JupyterHub were on AWS us-west-2, then we could direct connect to the S3 buckets and it would be as if we had downloaded the data. We can effectively “attach” a cloud drive with petabytes of data to our virtual machine.
Today we will be showing how to “stream cloud data without downloads”. Because we are on Azure and the data are in S3 us-west-2 buckets, we have to use “https” access. Be aware that https access without downloads is painfully slow on cloud-ignorant netCDF files. Of course, downloads of large datasets is also painfully slow. This is one of the reasons why providing cloud-optimized data formats is so important.
JupyterHubs (and virtual machines) can be easily spun up on any cloud provider and computing is cheap (storage is expensive). You do not need to install the compute environments. The common workflow is to run a provided docker image with docker run.
Lecture on NASA earth data in the cloud by Michele Thornton (NASA Openscapes) Video